The Culture of Devotion – And what TEI Encoding tells us about it
Authors: Haaf, Susanne
Date: Friday, 8 September 2023, 9:15am to 10:45am
Location: Main Campus, L 1.202 <campus:note>
Abstract
Introduction
In text linguistics, among other things we study the structuring of texts and the question if certain text types are structured in a certain, typical way. However, even though TEI encoded texts have been around for quite some time, now, in historical German linguistics works on exploiting TEI encoding in the context of text type analysis are rare.
In my dissertation thesis (Haaf: appearing), I studied the presence of typical language patterns in certain devotional text types, namely protestant funeral sermons and devotional prose texts of the 17th century. Comparing corpora, I extracted statistically relevant textual patterns of the named text types and asked for their respective functions for the text. My work also included an exploitation of TEI encoding – alone and in combination with potential textual patterns, which I plan to report on in my talk.
The thesis combined qualitative and quantitative methods: potentially significant features were gathered from previous qualitative research and were extracted from corpora using (semi-)automatic methods. The results, however, did not just allow for insights on relevant textual features but for conclusions based on these features on the specifics of devotional 17th century culture.
Related work
Though devotional literature was in its time highly relevant for people of all social ranks, it has only rarely been considered by linguistic, literary, or theological research (exceptions: esp. Pfefferkorn 2005; Kemper 2015). Moreover, despite vast qualitative research on the characteristics of text types in Germanic linguistics alone (overviews e.g. Heinemann 2000; Schuster 2017; bibliography: Adamzik 1995), the approach of exploiting large corpora in this context is relatively new.
Corpus linguistics considering text types focused on contemporary texts and the differentiation of widely disparate text types (e.g. Biber 1988), or on corpus driven methods (e.g. Scharloth 2018), one exception being Bubenhofer and Spieß 2012. Digital literary studies typically base text type differentiation on stylometry or topic modelling methods rather than linguistic featues (e.g. Schöch 2017; Hettinger et al. 2015; cf. Viehhauser 2017). All such studies almost never exploit TEI encoding in the corpora used.
Method & Corpora
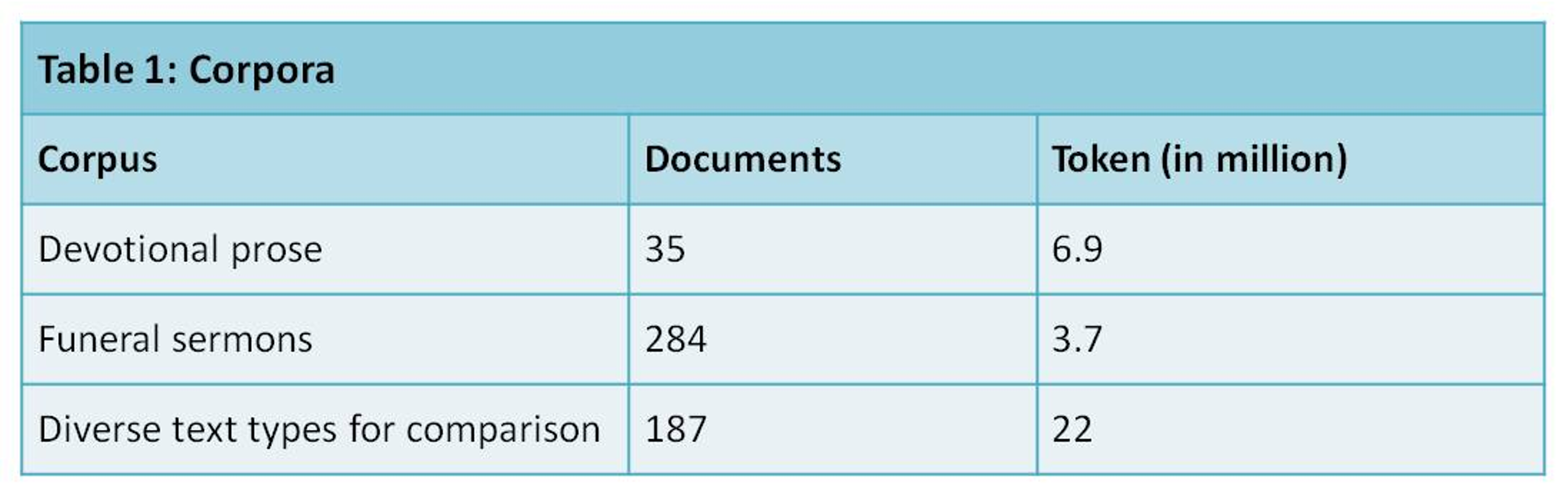
The current study was based on three TEI corpora (table 1), taken from the DTA (
2007–2023) collections. Those texts are encoded according to the DTA Base
Format (DTABf), a TEI P5 dialect which is meant to allow for homogeneous
annotation and interoperable outcome of historical texts (DTABf since 2011;
Haaf, Geyken, Wiegand 2014). Thus, information on text structures were available
for data analysis, but also on linguistic features of tokens. The latter are
gained by automatic procedures within the digitization and publication workflow
of the DTA (Jurish 2012), and one output format includes tei:w elements with
these information on token level based on the TEI att.linguistic class (
Bański, Haaf, Mueller 2017). Feature extraction in the current study was based
on this resulting format (DTABf + att.linguistic)1 and was done using XSLT
and Python technology.
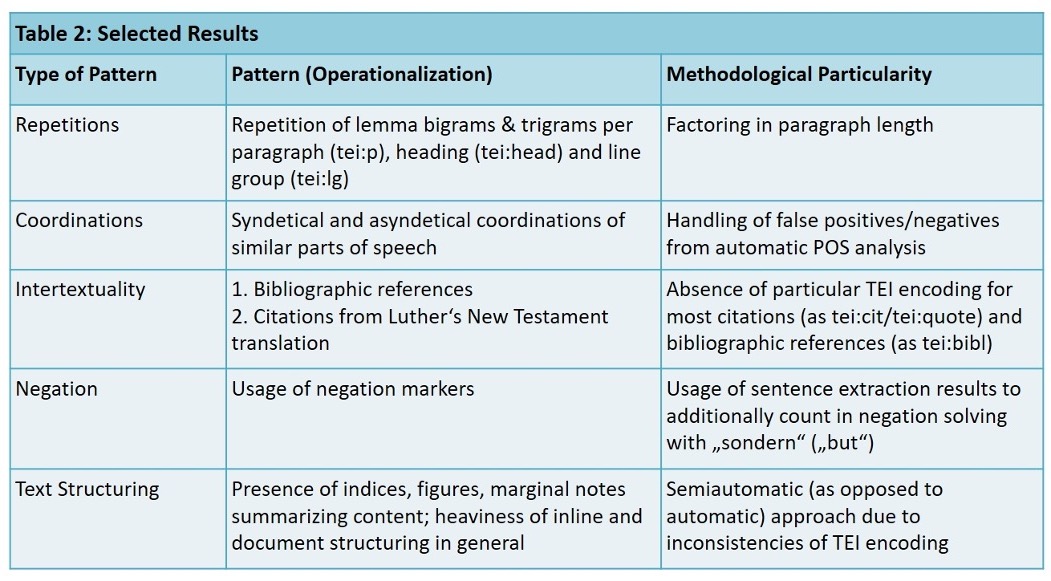
The study included nineteen features (see examples in table 2) from different textual layers (word, phrase, sentence, text), estimating significance by computing and evaluating measures of descriptive and analytical statistics (on frequency, distribution, and variance).
Results to present
The results show, that essential information on patterns of text types can be conveyed by TEI text structuring. This concerns layout specifics as well as typical combinations of textual structures and ways of phrasing.
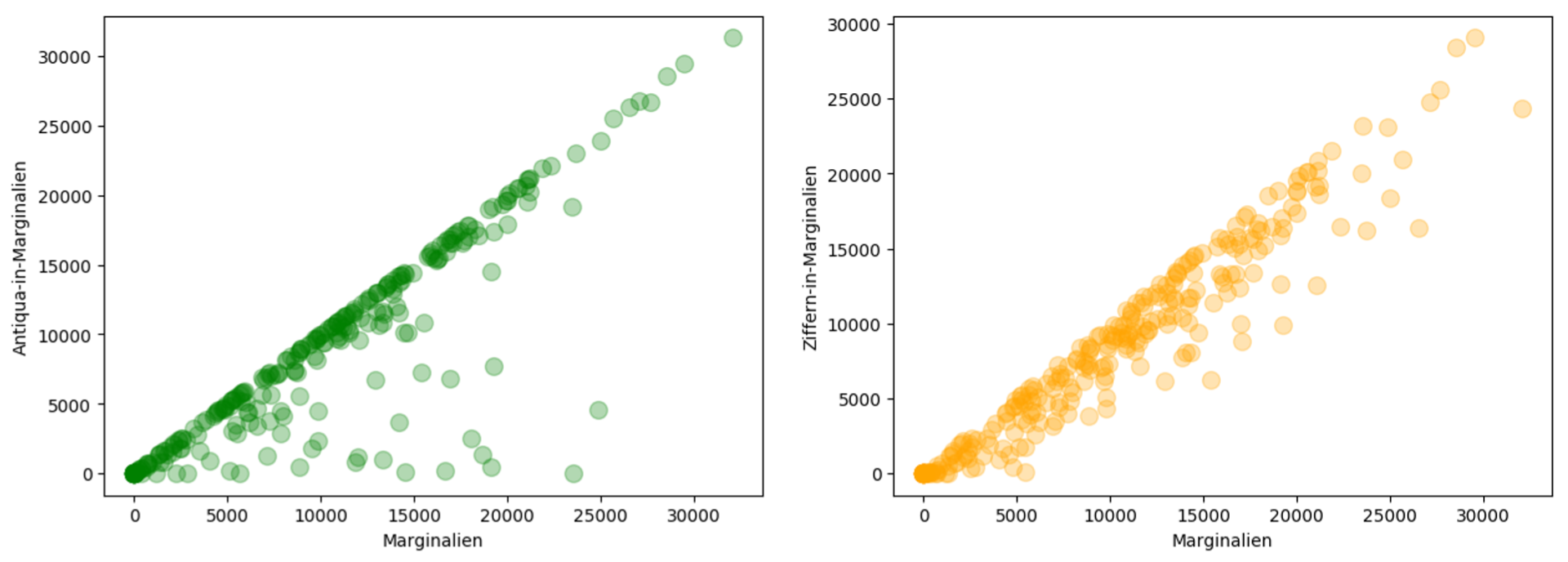
Thus, results from earlier qualitative analyses could now be specified by factoring in TEI encoding. For example, the finding that citations are essential to devotional literature could now be supplemented with information about how and where bibliographic citations are usually realized in a text (Img. 1).
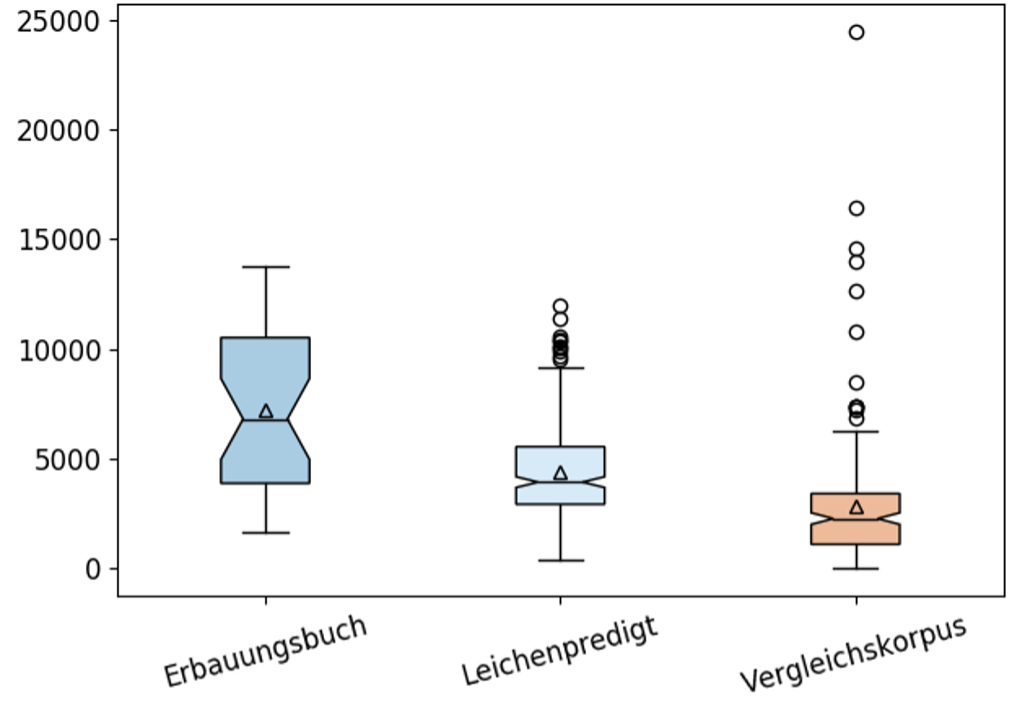
Furthermore, characteristic places of lexical repetition (Img. 2) could be specified along with the relevance of location for its emotionalizing effect ( repetitions in lists vs. paragraphs).
These are only examples of a range of results obtained by considering TEI encoding, which I would like to present. However, the talk shall also address limitations of the approach (i.e. limited annotation depth or lacks of interoperability as briefly listed in table 2), ways to stretch these limits, and requirements for markup depth in linguistic research data.
Finally, a model gained from the study’s results will be presented that shows intended effects of devotional literature and its significant textual and structural patterns, and thus allows for insights on German devotional culture of the 17th century.
Bibliography
Adamzik, Kirsten (1995): Textsorten - Texttypologie. Eine kommentierte Bibliographie (Studium Sprachwissenschaft 12). Münster.
Bański, Piotr, Susanne Haaf & Martin Mueller (2018): ‘Lightweight Grammatical Annotation in the TEI. New Perspectives’. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), 7.–12.05.2018, Miyazaki (Jp), 1795–1802. Online: https://aclanthology.org/L18-1283.pdf ( accessed 2023-06-20).
Biber, Douglas (1988): Variation Across Speech and Writing. 1st ed. (digital version of 2012). Cambridge et al. DOI: 10.1017/CBO9780511621024.
Bubenhofer, Noah, and Constanze Spieß (2012): ‘Zur grammatischen Oberflächenstruktur von Kommentaren: Eine korpuslinguistische Analyse typischer Sprachgebrauchsmuster im kontrastiven Vergleich’. In: Pressetextsorten jenseits der “News”. Medienlinguistische Perspektiven auf journalistische Kreativität, ed. by Christian Grösslinger, Gudrun Held, and Hartmut Stöckl (Sprache im Kontext 38), Frankfurt am Main, pp. 85–105.
DTA (since 2007): Deutsches Textarchiv. Grundlage für ein Referenzkorpus der neuhochdeutschen Sprache. Prepared by Matthias Boenig, Alexander Geyken, Susanne Haaf, Bryan Jurish, Christian Thomas, and Frank Wiegand. Ed. by Berlin Brandenburg Academy of Sciences and Humanities. Berlin. Online: https://deutschestextarchiv.de/ (accessed 2023-07-31).
DTABf (since 2011): Deutsches Textarchiv – Basisformat, ed. by Deutsches Textarchiv (DTA) and DTABf Steering Committee (Susanne Haaf, Matthias Boenig, Alexander Geyken, Christian Thomas, Frank Wiegand, Daniel Burkhardt, Stefan Dumont & Martina Gödel). Berlin. Online: https://deutschestextarchiv.de/doku/basisformat (accessed 2023-06-22).
Haaf, Susanne (in preparation): Die Musterhaftigkeit erbaulicher Textsorten des Deutschen. Ein integrativer Ansatz zu ihrer Untersuchung an der Schnittstelle von quantitativer und qualitativer Linguistik. Diss., Univ. Paderborn, 2022 (to appear 2023).
Haaf, Susanne, Alexander Geyken, and Frank Wiegand (2014): ‘The DTA “Base Format”. A TEI Subset for the Compilation of a Large Reference Corpus of Printed Text from Multiple Sources’. In: Journal of the Text Encoding Initiative (jTEI) 8. DOI: 10.4000/jtei.1114.
Heinemann, Wolfgang (2000): ‘Aspekte der Textsortendifferenzierung’. In: Text- Und Gesprächslinguistik. Ein internationales Handbuch Zeitgenössischer Forschung, ed. by Klaus Brinker, Gerd Antos, Wolfgang Heinemann, and Sven F. Sager (Handbücher zur Sprach- und Kommunikationswissenschaft 16.1), Berlin/New York, pp. 523–546.
Hettinger, Lena, Martin Becker, Isabella Reger, Fotis Jannidis, and Andreas Hotho (2015): ‘Genre Classification on German Novels’. In: Proceedings of the 26th International Workshop on Database and Expert Systems Applications (DEXA), IEEE, pp. 249–253.
Jurish, Bryan (2012): Finite-State Canonicalization Techniques for Historical German. Diss., Univ. Potsdam, 2011. Potsdam. Online: http://opus.kobv.de/ubp/volltexte/2012/5578 (accessed 2022-06-14).
Kemper, Karl-Friedrich (2015): Religiöse Sprache zwischen Barock und Aufklärung. Katholische und protestantische Erbauungsliteratur des 18. Jahrhunderts in ihrem theologischen und frömmigkeitsgeschichtlichen Kontext. Diss., Philosophisch-Theologische Hochschule SVD St. Augustin (Religionsgeschichte der frühen Neuzeit 22). Nordhausen.
Pfefferkorn, Oliver (2005): Übung der Gottseligkeit. Die Textsorten Predigt, Andacht und Gebet im deutschen Protestantismus des späten 16. und 17. Jahrhunderts. Habil., Univ. Halle-Wittenberg 2003 (Deutsche Sprachgeschichte 1). Frankfurt am Main.
Scharloth, Joachim (2018): ‘Korpuslinguistik für sozial- und kulturanalytische Fragestellungen’. In: Korpuslinguistik, ed. by Marc Kupietz and Thomas Schmidt (Germanistische Sprachwissenschaft um 2020 5), Berlin/Boston, pp. 61–80.
Schöch, Christof (2017): ‘Topic Modelling Genre. An Exploration of French Classical and Enlightenment Drama’. In: Digital Humanities Quarterly 11 (2). Online: http://www.digitalhumanities.org/dhq/vol/11/2/000291/000291.html (accessed 2022-02-11).
Schuster, Britt-Marie (2017): ‘Elemente einer Theorie des Textsortenwandels. Eine Bestandsaufnahme und ein Vorschlag’. In: Textsortenwandel vom 9. bis zum 19. Jahrhundert. Akten zur internationalen Fachtagung an der Universität Paderborn, 9.–13.6.2015, ed. by Britt-Marie Schuster and Susan Holtfreter (Berliner sprachwissenschaftliche Studien 32), Berlin, pp. 25–43.
Viehhauser, Gabriel (2017): ‘Digitale Gattungsgeschichten. Minnesang zwischen generischer Konstanz und Wende’. In: Zeitschrift für digitale Geisteswissenschaften (2). DOI: 10.17175/2017_003.
About the Author
Susanne Haaf holds a degree in German philology and Computational Linguistics (M. A.) from the University of Heidelberg. Currently, she works as a research associate at Berlin-Brandenburg Academy of Sciences and Humanities, where she has been engaged in the projects DTA, CLARIN-D, t.evo and (till present) ZDL, all of which involved the preparation and maintenance of TEI corpora. She finished and defended her PhD thesis at the University of Paderborn in 2022, which contains work on the computational analysis of patterns which differenciate historical devotional text types.
Notes
the selection of DTA download formats.
-
I am grateful to my former colleague Bryan Jurish who added this format to ↩
Contribution Type
Keywords